

Good decisions require data
Of course. Without some robust thinking and analysis based on data, it’s called (um) . . . guessing.
Even if you are not a “quant”, you better be able to explain what a regression is and roughly how it works. Look – we’ve all forgotten a lot of undergraduate statistics, but trust me, it’s useful to know what a p value is.
How data-analytics-ish are you?
Take a look at the spectrum I created below. Where are you, and more importantly, where should you be for your work?
- Left: willful detractor / cynic / curmudgeon of data analytics
- Right: enthusiastic savant / Github-fueled evangelist
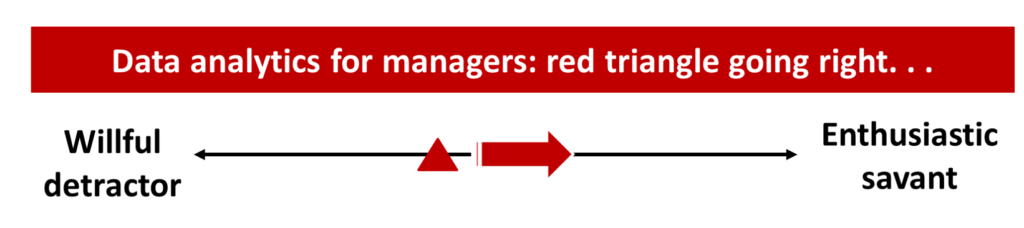

I am a proud liberal arts major, but not so proud about my illiteracy in Python, R, Javascript, and HTML (ddang, that’s a long list). That said, I am not a Luddite:
- As a B-school teacher, I understand the vast opportunities on the right
- As a manager, I need to be able to lead people who live on the right
- As a participant in the technology-first economy, I am the red triangle moving to the right
The world is awash is data
Recently read a book The Future is Faster than you Think, P Diamandis, S Kotler, 2020 here (affiliate link), and they make the case that we are at the convergence of multiple exponential technologies because computing (faster and cheaper) + storage (cheaper) + machine learning algorithms (getting smarter everyday). Perhaps you don’t need convincing of this fact, but some acronyms driving this big bang in data:
- ERP (enterprise resource planning). The big SAP, and Oracle investments from 10+ years ago are finally paying off
- IOT (internet of things). Yes, your watch, lightbulbs, front door, car are all spinning off data
- OCR (optical character recognition) of images and NLP (natural language processing) of voice. Keeps improving
- DTC (direct-to-consumer). Everyone wants a relationship with you (read: data link with your phone)
- API (application programming interface). Keep getting closer to nirvana of “plug and play” software integration
What are the basics you need to know?
I recently read The HBR Guide: Data Analytics Basics for Managers here (affiliate link). It’s 223 pg, twenty-two articles, and thankfully current (2018). Please find some of my key takeaways, from a non-quant perspective:
1.Clarify the purpose (why) before starting
Unless you are downloading a standardized “canned” report, there’s gonna be some ambiguity in the process. What data? What time range? What confidence level? Who can help me pull the data? What does clean data look like? The more you vet these questions in your own head, the less wasted time and uber-frustration you are going to feel. So, take a minute and crystalize your thinking. It’s okay to go slow (so you can go faster later).
2. Keep it simple. Can you explain it to your cousin?
For those of us who work in Fortune 500 or consulting firms with dedicated analytics functions, it’s easy to be enamored by all the whiz-bang talk of data lakes, Hadoop, and Snowflake. It’s cool, mysterious, almost a siren call. Yo, Ulysses – wake up. Even if you don’t do the analysis, you need to understand it. As Deloitte CFO, Frank Friedman said, “If I cannot articulate it, I cannot defend it to others.” This is a crazy direct, and useful piece of advice. Don’t “go admin” and become a consulting mailman who just pretties up the numbers on a PowerPoint slide.
Great story: Apparently, the CEO of TD Bank (Canada) insisted that managers be able to explain the math behind their financial products, and as a result, they largely avoided the arcane, toxic, leveraged derivative products that lead to the financial crisis of 2008.
3. Stay intellectually honest
Getting useful insights takes effort, and often, failure. Hypothesis-based consulting is usually the right approach because you don’t cannot analyze everything. It’s the smart way to go, and yet, it also means that your are often proven wrong (think: null hypothesis). So, it can be tempting to take short-cuts. Just use the data you have. Just remove a few outliers that make no sense. Just do it.
Confession time: we have all been guilty of torturing data until it says what we want. So, as professionals . . .
- Let’s commit to a plan and stick with it; be transparent about the approach (# of observations, time, variables)
- Let’s not run the experiment until we get the results we want (replication bias)
- Let’s allow dead-ends die. Instead, stay curious and test out a different hypothesis
Trust me, this is actually harder than it sounds. Think: confirmation bias, overconfidence bias, overfitting bias, etc. . .
4. Be familiar (enough) with regression analysis
HBR describes regression analysis as the workhorse of analytics, so we better have some working idea of what it is and how to use it. Here is a 3 bullet point version. As you can imagine, there are entire courses on Coursera on the topic, so consider this the Twitter-version.
- Official version: Regression analysis is a statistical technique to determine the relationship between a single dependent variable (criterion) and one or more independent (predictor) variables.
- Less wonky version: Regression analysis mathematically helps you understand to what extent A, B, C, D affect X.
- No regression will be perfect, so there will be an “error term”
- As you might imagine, the smaller the error term, the better the explanation power of the formula
- Yes, the more variables you add to the formula, the smaller the error . . but a formula with 2,000 variables = useless
Maybe a simple example would help. Let’s say we own a gas station and want to know what affects our sales (X). We might put a bunch of data into a regression formula including the weather (A), the day of the week (B), and the difference between our posted gas price and competitor’s price (C), to see which factors had the greatest influence on sales.
5. Use analytics to ask better questions
Thomas Redman, the “Data Doc”, said, “The goal is not to figure out what is going on with the data, it is to figure out what is going on in the world.” BOOM. Deep. As a managers, we need to think of regression analysis (or any analytical tool) as a means to ask better questions and get more confident in our thinking:
- How do you go about choosing relevant variables?
- Which variables matter most? Which ones can we ignore?
- How do these variables interact with one another?
6. Recall, correlation is not causality
Correct. Black umbrellas do not cause rain.
7. Recall, life is not a straight line
As seasoned consultants, we know that trend lines are rarely straight lines. Market share gets saturated. Demand elasticity of price changes. The slope (remember rise/run?) changes over time. Whether it is customer lifetime value, mortgage amortization, or unit profitability, this varies. Without even labeling the X or Y axis, you can probably think of business situations where you see these scenarios.

8. Get good (enough) data
Okay, what’s “good enough” look like? In a perfect world, the data you seek would be abundant, easy to get, cheap, unbiased, structured, and almost self-explanatory. It’s like being a chef with an infinite pantry of fresh ingredients.
Since we know that is unrealistic, we need to evaluate trade offs:
- Any publicly available data, or already validated data sets that can be repurposed?
- Can we start with structured data sets; clean, check, and work with first?
- Do we have a large and representative enough sample size to be valid?
- Do we know the source and definition of the data sets?
- Can we set up experiments to test the data validity?
9. No really, cleanse your data
Nothing is worse that analyzing, visualizing bad data. It’s like cooking with rotten ingredients; it’s inedible.
- Look for missing values, convert text to number, clean up typos (e.g., Walmart, Wal-mart, Wallmart, Wal*Mart)
- Identify outliers and determine relevance, and how to arbitrate
- Create a sample set you can trust, then use it to stress-test the larger, uncleaned data
- Cross-walk the data carefully (vlookup, concatenate), keeping an audit trail of your edits
- Document the data definitions and get buy-in from stakeholders you will present analyses to
10. Stay involved in the experiment design
As the business owner (working with an analytics team), you’ll be super involved in the beginning and the end of the process. It’s up to you to help define the key questions (and hypotheses you are testing). Yes, you need to trust the analytics team, but also (yes) verify as you go:


Make sure that you are studying a treatment group that looks, feels, sounds like your target. It’s easy to go for the cheapest, easiest common denominators (read: free online surveys), but let’s agree that will skew young, digital, and bored. Randomize people into the treatment and control groups. Yes, you should pick them. Don’t let them self-select (uh, I want to be in the financially literate group, please).
Be your own best advocate. Wait long enough to get a good sample size. Limit the metrics to something reasonable, and please, please, please – retest. If you are working on a problem that’s big enough to bother. . . retest.
11. Don’t be subtle with the experiment(s)
One of the more provocative points from the HBR guide was the advice that you should “use a big hammer” when piloting experiments. As counterintuitive as this seems at first, this “go big or go home” war cry makes sense:
- There is a lot of noise, and it’s too easy for weak signals to get lost
- You are testing a hypothesis, and can always follow up with more nuanced, particular experiment(s)
- The eventual implementation will likely get watered down, so start out with a 80 proof intervention
12. A/B test
Just like it sounds, A/B testing is the most basic kind of randomized experiment. It’s an old idea – give the same things to two sets of people with only 1 thing changed. . then see if that makes a meaningful difference. Of course, the online-first companies (e.g., GOOG, FB, ABNB) can spin up hundreds of different A/B micro-experiments on you, without you ever noticing. Need convincing? Watch “Social Dilemma” documentary on Netflix.
Of course, it’s more sophisticated now. Firms can multivariate test A/B/C/D combinations; craftily test different combination subsets (think: conjoint analysis) and infer the rest. Whatever “lift” they can get between the control and test group is awesome, and probably pays for itself.
13. Shoot for a low “p value”
With any experiment, you are testing a sample of a larger population. So the size of the sample, and underlying variation within that population matters. This is where “p value” comes in. A low p value = more confidence that the results are not purely by chance. Apparently, statistically significance varies by context. . . in other words, a scientific academic article might look for a p value < 0.05, but in business a p value as high as 0.2 might be acceptable, useful, and profitable. Thinking of it this way:
- $$$$ impact x high p value (less significant). . still go for it
- $ impact x low p value (highly significant). . .perhaps not worth it
14. Tell a story with the data
As consultants, we know that the data will not explain itself. It’s up to us to understand the business context, logically structure the choices, and give our executive clients the courage to act. As Chris Anderson (Wired magazine) explained, sometimes it’s impossible or unnecessary to show causality: “Petabytes allow us to say: “correlation is enough.”
15. Prevent the yo-yo
It’s pretty common to see backsliding when the project ends and no one is watching (read: anti-Hawthorne effect). Just like your weight yo-yos after ending the diet, it’s too easy to fall into old, bad habits. So what can we do to hardwire the changes by implementing automated metrics tracking, and better data practices? Just like they taught you in school, “leave the place better than you found it.”


16. Find great data scientists
This was a fun way for HBR to end. They listed several ways to find and recruit data scientists:
- Scan membership rolls of user groups (R, Python)
- Hang out with data scientists at Strata, Structure:Data, Hadoop World
- Make friends with local venture capitalists – who’ve gotten lots of proposals
- Host a competition on Kaggle or TopCoder
- Don’t bother with candidates how can’t (do some) code
- Make sure a candidate can find a story in a data set
- Be wary of candidates who are too detached from the business world
- Ask candidates how they are keeping their skills sharp
- See if they’ve contributed to an open-source project, or contributed to GitHub?